Private AI Development Assistants: How IT Companies Can Turn Internal Knowledge Into Faster Delivery
Every software company has the same hidden problem. Knowledge is everywhere, but it is not organized. Some information is in documentation. Some is in Jira tickets. Some is inside GitHub pull reques...
Every software company has the same hidden problem.
Knowledge is everywhere, but it is not organized.
Some information is in documentation. Some is in Jira tickets. Some is inside GitHub pull requests. Some is in Slack messages. Some is only in the head of senior developers. Some is buried inside old code. Some is written in onboarding documents that nobody updates.
This creates a real operational cost.
New developers need more time to become productive. Senior developers repeat the same explanations again and again. Project managers create vague tasks that need several rounds of clarification. Developers spend hours searching for the right file, the right service, the right business rule, or the right deployment process.
AI can help with this, but only if it is built correctly.
Most companies think about AI in software development only as “using ChatGPT”, “using Claude Code”, or “using Codex”. These tools are powerful, but they do not automatically understand your company, your repositories, your clients, your processes, your internal rules, your delivery standards, or your project history.
For IT companies and software agencies, the real opportunity is bigger.
The opportunity is to build a private AI development assistant that works with your internal knowledge, your codebase, your onboarding process, your tasks, and your development workflow.
That is exactly what our offer is designed to do.
We help software companies build a private AI development and company knowledge platform within a 3-month pilot for a fixed implementation fee.
The goal is not to create another chatbot.
The goal is to create an internal AI layer that helps your team deliver software faster, onboard developers faster, reuse company knowledge better, and turn requirements into structured development work.
Download detailed offer and prices: https://entro.solutions/wp-content/uploads/2026/05/Private_AI_Development_Assistant_Offer.pdf
Why IT Companies Need More Than a Chatbot
A normal chatbot answers questions.
A useful internal AI system does much more.
It should understand your company documents. It should know where project knowledge is stored. It should process onboarding guides. It should search repositories. It should understand technical specifications. It should help create task flows. It should help developers inspect code, generate implementation plans, run tests, and prepare pull requests.
This is the difference between a basic AI assistant and a real AI development system.
A basic chatbot can answer:
“What is Laravel?”
A real internal AI assistant can answer:
“Where is the billing logic implemented in our subscription platform, what files are affected if we add trial expiration emails, what tests should be created, and what pull request checklist should the developer follow?”
That is the level of value software companies need.
The Problem With Company Knowledge
Most software companies already have the knowledge they need.
The problem is that it is not structured.
It is spread across:
Internal documentation
README files
Architecture documents
Client briefs
Technical specifications
Deployment guides
Jira, Linear, Trello, or ClickUp tasks
GitHub or GitLab repositories
Pull request discussions
Slack or Teams messages
Database schema notes
Old bug reports
Onboarding guides
When a new developer joins, they do not receive a clear map of the company knowledge. They receive links, repositories, scattered documents, and messages from different people.
When a developer starts a task, they often need to ask:
Where is this feature implemented?
What business rule should I follow?
Is there already a service for this?
Which tests should I run?
What is the correct deployment process?
Who owns this module?
Has this bug happened before?
This creates friction.
It also creates dependency on senior developers. The more the company grows, the more senior people become a bottleneck.
A private AI knowledge layer solves this by turning scattered information into structured company know-how.
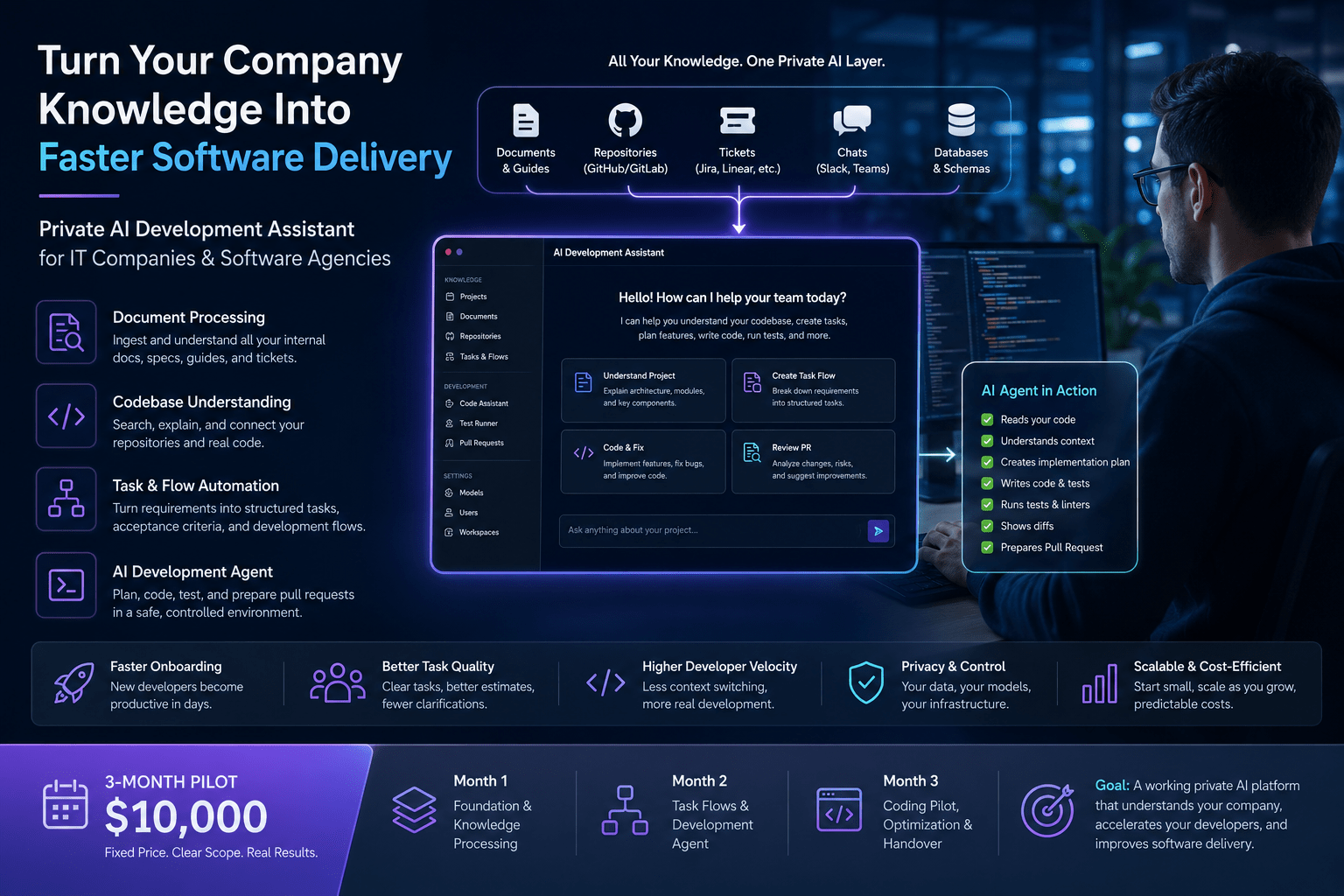
What We Build
We build a private AI development assistant for software companies and agencies.
The platform combines four important layers.
First, we build a document processing and company knowledge layer. This processes internal documents, technical specifications, onboarding guides, project documentation, and other company materials.
Second, we build a repository understanding layer. This allows the AI to search code, understand files, explain modules, and connect technical tasks with real code.
Third, we build a task flow engine. This turns client requirements, project manager notes, tickets, or internal requests into structured development tasks with acceptance criteria, affected files, risks, and test plans.
Fourth, we build a Claude Code-style development agent. This allows the AI to inspect code, create implementation plans, apply controlled patches, run tests, fix errors, show diffs, and prepare pull requests for human review.
The result is a private AI system that supports both knowledge work and real development work.
How the Document Processing Layer Works
The first step is to process the company’s internal knowledge.
We can ingest materials such as internal documentation, onboarding guides, technical specifications, architecture documents, README files, deployment notes, project requirements, API documentation, database schema notes, client briefs, project tickets, and repository documentation.
The system extracts the content, cleans it, splits it into logical sections, detects the project or module context, removes duplicate content, scans for sensitive values, attaches metadata, generates embeddings, and stores everything in a searchable knowledge base.
This means the AI does not answer only from memory. It answers from your actual company knowledge.
A good AI answer should include sources. If the assistant says something about a deployment process, it should know where that information came from. If it explains a project module, it should connect that explanation to the right documentation or repository files.
This is how trust is built.
Turning Documents Into Company Know-How
Document search is useful, but it is not enough.
The real value comes when the system starts creating structured company know-how.
For each project, the AI can help build and maintain:
Project overview
Business purpose
System architecture summary
Main modules
Important repositories
Local setup guide
Main commands
Database overview
API overview
Deployment process
Testing process
Coding standards
Pull request rules
Known risks
Common bugs
Common questions
Onboarding path
Task creation rules
This gives every developer a clear starting point.
Instead of asking a senior developer to explain the same project again, a new team member can ask the AI:
“Explain this project like I am joining the backend team today.”
The assistant can return a project overview, the main modules, important files, local setup steps, common issues, first tasks, and testing commands.
This reduces onboarding time and makes project knowledge reusable.
Creating Development Flows From Requirements
Many software tasks start with unclear requirements.
A client says:
“We need better subscription reminders.”
A project manager creates a short task.
A developer then needs to investigate the codebase, understand the business logic, ask follow-up questions, find affected files, decide what tests are needed, and define the final implementation.
This is exactly where an AI task flow engine helps.
The assistant can transform a simple request into a structured development flow.
For example:
“Add trial expiration reminder emails 3 days before the subscription ends.”
The system can generate:
Business goal
Technical tasks
Affected files
Acceptance criteria
Test plan
Risks
Documentation updates
Pull request checklist
A good generated task flow could include:
Review the Subscription model.
Check if a trial_ends_at field already exists.
Add a scheduled command or queued job.
Query users whose trial ends in 3 days.
Create a notification or email template.
Prevent duplicate reminders.
Add feature tests.
Update billing documentation.
Run the relevant test suite.
This creates better tasks, better estimates, and better developer execution.
AI That Works With the Codebase
For software companies, the AI must work with real repositories.
This is where a Claude Code-style agent becomes valuable.
The development agent can work inside a repository and use controlled tools such as:
Read files
Search code
List project structure
Find related files
Create implementation plans
Apply patches
Run tests
Run linters
Show git diffs
Prepare commits
Prepare pull requests
The important point is control.
The AI should not have unrestricted access to the server. It should work through a secure agent layer that controls what the AI is allowed to do.
For example, the assistant can run tests, but it should not deploy to production. It can read application files, but it should not read .env files or private keys. It can prepare a pull request, but a human developer should review and approve it.
This makes AI useful without making it dangerous.
Safe Development Sandbox
Every coding task should happen inside a safe workspace.
The system can create a temporary branch or worktree, inspect the repository, apply patches, run tests, and show the final diff.
The assistant should not access production secrets. It should not run destructive commands. It should not execute deployment scripts. It should not wipe databases. It should not modify production configuration without approval.
A safe AI development workflow looks like this:
A developer gives a task.
The agent creates a temporary branch.
The AI reads project instructions.
The AI searches relevant code.
The AI creates a plan.
The developer approves the plan.
The AI applies code changes.
The system runs tests and linters.
The AI fixes errors if tests fail.
The agent shows the final diff.
The developer approves the commit or pull request.
This is how AI becomes a development assistant, not an uncontrolled automation risk.
Local Open Models vs Claude Code and Codex
Claude Code and Codex are excellent tools.
They are fast to start with, they provide a good developer experience, and they are powerful for individual developers and teams.
But many IT companies need more control.
A private system using open models gives the company more flexibility over data, workflows, integrations, and cost structure.
With self-hosted open models, the company can keep more knowledge inside its own infrastructure. It can integrate deeply with internal documentation, repositories, client projects, ticket systems, and delivery workflows. It can also switch between models such as Qwen, DeepSeek, and Kimi depending on performance and cost.
The tradeoff is that self-hosting is more complex. It requires GPU infrastructure, monitoring, model benchmarking, and secure orchestration.
That is why our recommendation is practical.
We do not suggest replacing Claude Code and Codex immediately across the whole company.
We suggest building a private pilot that focuses on the company’s own advantage: internal knowledge, internal code, internal workflows, and agency-specific delivery processes.
Which Open Models Can Be Used
There are several strong open model families that can be tested.
Qwen is a practical starting point for daily coding workflows. It has strong coding-focused models and is a good candidate for repository understanding, task planning, test generation, and patch creation.
DeepSeek is another strong option for coding and reasoning. It is useful for code explanation, backend development tasks, bug fixing, and testing workflows.
Kimi is a strong option for more complex reasoning and advanced agentic workflows. It can be valuable for architecture analysis, large refactors, complex debugging, and high-value development tasks. However, Kimi can be more expensive to self-host properly because the larger models require serious GPU infrastructure.
The best approach is model-agnostic.
We build the platform so it can test multiple models and switch between them. During the pilot, we benchmark Qwen, DeepSeek, and Kimi on real company tasks instead of guessing.
Infrastructure and Cost
For the pilot, we recommend starting with a practical GPU setup instead of overbuilding from day one.
A smaller pilot can run on a lower-cost setup for document processing, knowledge search, and limited coding-agent workflows.
A stronger pilot can use more powerful GPU instances for better coding model performance and more active users.
For a software agency with around 120 people, we should not assume that all 120 users will run AI coding tasks at the same time. A realistic architecture should calculate active concurrency. In many companies, only 10 to 25 percent of users may be active at the same time, especially for heavier coding-agent tasks.
A practical pilot can start with a controlled number of users, selected repositories, selected documents, and selected workflows. After that, the company can scale based on real adoption and measured value.
Our 3-Month Pilot Offer
We offer a 3-month pilot implementation.
The goal is to build a working private AI development and knowledge platform, not just a demo.
Month 1: Foundation and Knowledge Processing
In the first month, we set up the technical architecture, model runtime, document ingestion pipeline, vector database, first repository import, basic knowledge search, and security rules.
The result is a working foundation for company know-how and repository understanding.
Month 2: Task Flows and Development Agent
In the second month, we build the company know-how builder, onboarding flow generation, task breakdown workflow, bug-fix workflow, pull request review workflow, repository search tools, file reading tools, safe workspace setup, patch generation, and git diff output.
The result is an assistant that can understand documents, understand repositories, generate task flows, and create safe code change proposals.
Month 3: Coding Pilot and Handover
In the third month, we add controlled file editing, test execution, linter execution, error analysis, the test-fix loop, pull request preparation, model comparison, infrastructure recommendation, documentation, and handover.
The result is a usable internal pilot that can support real development tasks under human review.
What Is Included
The pilot includes:
Architecture design
Model selection strategy
Self-hosted model runtime setup guidance
Model benchmarking setup
Document processing pipeline
Company knowledge base structure
Project know-how generation
Onboarding flow generation
Task breakdown workflow
Bug-fix workflow
Pull request review workflow
Repository search and code understanding
Claude Code-style agent prototype
Safe sandbox rules
Patch and diff workflow
Test runner integration
Pull request preparation workflow
Model comparison report
Infrastructure recommendation
Technical documentation
Final handover
What Is Not Included
The pilot does not include GPU server monthly costs, large production cluster management, fine-tuning custom models, full enterprise SSO implementation, full migration of all company documents, production rollout to all 120 users, or guaranteed replacement of Claude Code or Codex across every workflow.
The purpose of the pilot is to prove value, define the correct model strategy, test real workflows, and prepare a safe path to production.
Who This Is For
This offer is a good fit for:
Software agencies
IT outsourcing companies
Product development companies
SaaS companies with internal engineering teams
Companies with many repositories and scattered documentation
Teams that onboard developers often
Companies that want better task planning and codebase understanding
Organizations that care about privacy and control over internal knowledge
If your team repeatedly loses time because developers cannot find the right information, onboarding takes too long, senior developers answer the same questions repeatedly, or tasks are not detailed enough before development starts, this system can create immediate value.
Final Thought
AI in software development is not only about generating code.
The bigger opportunity is to connect AI with the company’s real knowledge, real projects, real repositories, and real delivery process.
A private AI development assistant can help your company turn scattered information into structured know-how. It can help developers understand projects faster. It can help project managers create better tasks. It can help teams prepare better pull requests. It can reduce repeated explanations and improve delivery quality.
That is the future we are building.
If your IT company wants to explore a private AI development assistant using open models, internal knowledge processing, task flow automation, and safe coding-agent workflows, we can help you build the first working pilot in up to 3 months.
Download detailed offer and prices: https://entro.solutions/wp-content/uploads/2026/05/Private_AI_Development_Assistant_Offer.pdf
This is not a chatbot project.
This is the first step toward a private AI operating layer for your software company.